
大语言模型中的规范性推理:从逻辑与模态视角的对比基准
论文原始标题:Normative Reasoning in Large Language Models: A Comparative Benchmark from Logical and Modal Perspectives
论文作者:Authors: Kentaro Ozeki, Risako Ando, Takanobu Morishita, Hirohiko Abe, Koji Mineshima, Mitsuhiro Okada
原始摘要:Normative reasoning is a type of reasoning that involves normative or deontic modality, such as obligation and permission. While large language models (LLMs) have demonstrated remarkable performance across various reasoning tasks, their ability to handle normative reasoning remains underexplored. In this paper, we systematically evaluate LLMs' reasoning capabilities in the normative domain from both logical and modal perspectives. Specifically, to assess how well LLMs reason with normative modals, we make a comparison between their reasoning with normative modals and their reasoning with epistemic modals, which share a common formal structure. To this end, we introduce a new dataset covering a wide range of formal patterns of reasoning in both normative and epistemic domains, while also incorporating non-formal cognitive factors that influence human reasoning. Our results indicate that, although LLMs generally adhere to valid reasoning patterns, they exhibit notable inconsistencies in specific types of normative reasoning and display cognitive biases similar to those observed in psychological studies of human reasoning. These findings highlight challenges in achieving logical consistency in LLMs' normative reasoning and provide insights for enhancing their reliability. All data and code are released publicly at https://github.com/kmineshima/NeuBAROCO.
翻译标题:大语言模型中的规范性推理:从逻辑与模态视角的对比基准
翻译摘要:规范性推理是一种涉及规范或义务模态(如义务和许可)的推理类型。尽管大型语言模型(LLMs)在各种推理任务中表现出色,但它们处理规范性推理的能力仍鲜有研究。在本文中,我们从逻辑和模态视角系统地评估了LLMs在规范领域中的推理能力。具体而言,为了评估LLMs如何处理规范模态,我们比较了它们在规范模态与认知模态(如“可能”和“确定”)中的推理表现,这两种模态具有共同的形式结构。为此,我们引入了一个新的数据集,涵盖了规范和认知领域中的广泛推理模式,同时整合了影响人类推理的非形式认知因素。我们的结果表明,尽管LLMs通常遵循有效的推理模式,但在某些类型的规范推理中表现出明显的不一致,并呈现出与心理研究中观察到的人类认知偏差相似的偏差。这些发现突显了在LLMs的规范推理中实现逻辑一致性的挑战,并为提高其可靠性提供了见解。所有数据和代码均在 https://github.com/kmineshima/NeuBAROCO 公开。
论文导览:

智能问答:
Q1: 这篇论文试图解决什么问题?
论文旨在系统评估大语言模型(LLM)在规范性推理(normative reasoning)上的能力,核心关注以下问题:
逻辑一致性
LLM 能否在涉及义务、许可、禁止等义务模态(deontic modality)的推理中,稳定地遵循有效/无效的逻辑模式?
例如,给定前提 OA(“必须做 A”),能否正确推出 PA(“允许做 A”)?其逆否命题 ¬PA ⇒ ¬OA 是否被同等对待?
与认知模态的对比
义务推理与认知模态(epistemic modality,如“可能”“确定”)在形式结构上有共通之处。论文通过并行测试,检验 LLM 在两域中的表现差异,揭示是否存在领域特异性(domain specificity)。
非形式因素的影响
除逻辑结构外,内容效价(是否符合常识)与语句是否含否定,会显著影响人类推理。论文验证 LLM 是否表现出类似内容效应(content effect)与否定敏感性(negation sensitivity)。
构建基准
为此,作者发布了 NeuBAROCO 数据集,涵盖
11 组义务逻辑基本模式(含 Ross 悖论、自由选择推理等争议案例)
8 组义务/认知三段论模式(含 MP、MT、AC、DA 及其否定变体)
三种内容类型(符合常识、违背常识、无意义词)
以支持可重复的比较实验。
综上,论文试图回答:当前 LLM 在规范性推理中是否具备可靠的逻辑一致性?其错误模式是否复现了人类认知偏差?
Q2: 有哪些相关研究?
以下研究被论文直接或间接引用,可划分为六个主题,均与“大语言模型如何做规范性/模态推理”密切相关。
义务逻辑与规范性推理(Deontic & Normative Logic)
von Wright (1951) 义务逻辑奠基,提出 OA/PA 对偶及 Deontic Square。
Kamp (1973) 自由选择许可悖论(Free Choice Permission)。
Ross (1941) Ross 悖论:OA ⇒ O(A∨B) 的直观无效性。
McNamara & Van De Putte (2022) 当代义务逻辑综述。
Gabbay et al. (2013) 《Handbook of Deontic Logic》体系化整理规范系统。
认知逻辑与模态推理(Epistemic & Modal Logic)
Hintikka (1962) 认知逻辑经典框架,引入“知道”算子。
Rendsvig et al. (2024) 斯坦福百科“Epistemic Logic”条目,总结最新形式结果。
Holliday et al. (2024) 首次系统评测 LLM 在认知模态推理上的盲点,发现对条件与否定敏感。
LLM 逻辑与三段论评测(Logical & Syllogistic Benchmarks)
Clark et al. (2020) Transformers as Soft Reasoners,提出用自然语言模板测试逻辑蕴涵。
Ando et al. (2023) NeuBAROCO 初代版本,揭示 LLM 在三段论任务中复现人类偏差。
Eisape et al. (2024) 人类与 LLM 的系统性三段论对比,指出否定与内容效价是主要难度来源。
Bertolazzi et al. (2024) 大规模三段论基准,量化模型规模与推理一致性之间的关系。
Lampinen et al. (2024) 内容效应在 LLM 中的跨任务泛化验证。
社会-规范内容偏差(Social & Normative Biases)
Sheng et al. (2021) 生成文本中的社会规范偏见度量。
Navigli et al. (2023) 对 LLM 偏见的全面盘点,包含道德与法律维度。
Almeida et al. (2024) 探索 LLM 在道德与法律推理中的心理学特征,发现其判决受文化提示影响。
领域特异性与进化心理学(Domain-Specific Reasoning)
Cosmides (1989); Cosmides & Tooby (1992) 社会交换理论:人类在“义务-违规”情境下表现更好。
Fiddick (2004) 区分义务、风险与亲属推理的实验证据。
Cheng & Holyoak (1985) 实用推理图式:规范规则比描述性规则更易被正确推理。
Seals & Shalin (2024) 首次在 LLM 中复现“社会内容优势”效应,但效应弱于人类。
提示策略与推理增强(Prompting & Reasoning Elicitation)
Brown et al. (2020) Few-shot prompting 显著提升逻辑任务表现。
Wei et al. (2022) Chain-of-Thought prompting 可激发逐步推理。
Kojima et al. (2022) Zero-shot CoT 无需样例即可触发逐步答案,但后续研究(包括本文)发现其稳定性有限。
这些研究共同构成了本文的学术背景:
形式层面——义务/认知逻辑提供有效/无效模板;
认知层面——人类偏差给出预期错误模式;
模型层面——既有 Benchmark 与 prompting 方法提供评测基线。
Q3: 论文如何解决这个问题?
论文采用“构建基准 + 系统实验 + 多维诊断”的三段式路线,把“LLM 能否稳定地做规范性推理”这一抽象问题转化为可量化的评测任务。具体步骤如下:
构建平行基准 NeuBAROCO
a. 形式模板
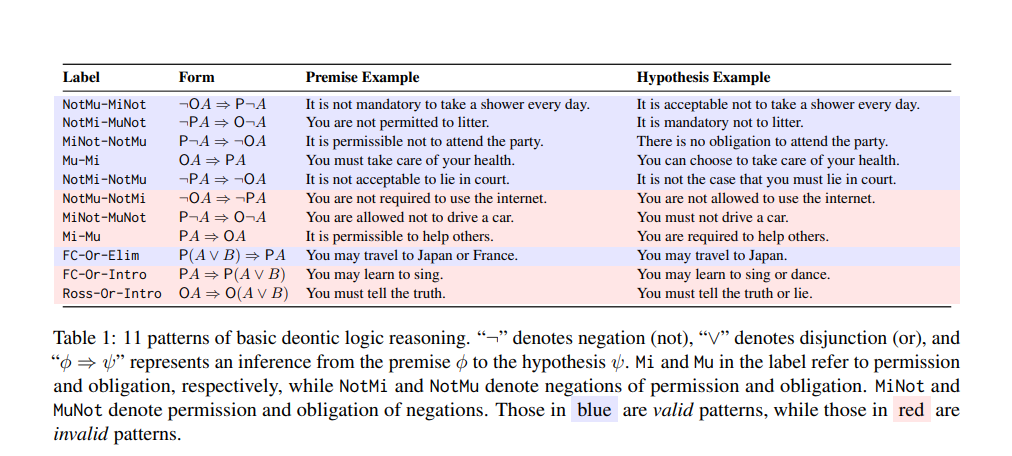
义务逻辑:11 种单前提推理模式(表 1),覆盖 Deontic Square、自由选择悖论(FC-Or-Elim/Intro)、Ross 悖论等。
义务/认知三段论:各 8 种双前提模式(表 2/7),按 MP/MT/AC/DA × 范畴/条件句 × 否定/非否定 交叉。
b. 内容变量
每条模板用 20 组具体词汇实例化,再按“符合常识 / 违背常识 / 无意义词”三类内容(表 4)各复制一次,形成 640+480 条义务题、480+480 条认知题。
c. 标注规则
有效/无效标签以 Standard Deontic Logic 和认知逻辑 K/T 系统为准;悖论类题目额外标注“人类直觉无效”。
模型与提示策略正交实验
模型:GPT-4o、GPT-4o-mini、Llama-3.1-8B-In、Llama-3.3-70B-In、Phi-4,共 5 个规模与架构不同的指令微调模型。
提示:Zero-Shot、Few-Shot(每模式给 1 例)、Zero-Shot-CoT 三条件,温度=0,单轮 deterministic 评测。
指标:Accuracy 为主,辅以“同模型内跨模式一致性”与“同模式跨内容稳定性”。
多维诊断分析
a. 逻辑一致性
检查“OA ⇒ PA”与“¬PA ⇒ ¬OA”是否同时被判对;发现 GPT-4o 在前者仅 56 % 而后者 100 %,暴露 contrapositive 不一致。
b. 领域特异性
义务 vs 认知整体准确率对比:Syllogistic 任务义务略高(符合人类社会推理优势),Deontic Logic 任务义务反而更低,说明“领域易度”随任务类型而变。
c. 内容效应
在 Deontic Logic 中,除 Phi-4 外所有模型在“违背常识”题下降 10–20 %;Syllogistic 中“无意义词”题普遍再降 10 %,与人类偏差一致。
d. 否定敏感性
MT/DA 两类含否定前提的模式普遍比 MP/AC 低 20–40 %;错误案例分析显示模型把“can choose to”当成“可选而非被允许”,揭示词汇级语义干扰。
e. 提示策略效用
Few-Shot 在义务逻辑提升 5–15 %,但在 Llama 三段论反而下降,提示“样例匹配”可能掩盖真实推理缺陷。
CoT 常引入中间步自我矛盾,导致 Deontic Logic 准确率下降或持平,说明逐步解释并非稳定解药。
通过上述“基准-实验-诊断”闭环,论文把“规范性推理是否可靠”拆解为可观测的指标,定位到
义务→许可这一基础推理链条断裂,
否定与内容效价放大了不一致,
领域优势并非绝对,
现有提示法无法根本修复逻辑缺陷。
从而给出明确答案:当前 LLM 在规范性推理上尚未达到可部署的逻辑一致性,需针对性改进训练或推理机制。
Q4: 论文做了哪些实验?
实验围绕两条任务链、三变量、五模型、三提示展开,形成 2×3×5×3=90 组主实验条件,每组均一次性 deterministic 评测,共 2 800 条题目。具体设计如下:
任务与数据集
a. Deontic Logic Task
11 种义务逻辑模式(表 1)× 3 内容类型(Congruent/Incongruent/Nonsense)× 20 词汇实例
义务侧 640 题(360 有效/280 无效);认知侧 480 题(300 有效/180 无效)
b. Syllogistic Task
8 种三段论模式(表 2/7)× 3 内容类型 × 20 词汇实例
义务侧 480 题(240 有效/240 无效);认知侧 480 题(240 有效/240 无效)
被试模型
GPT-4o & GPT-4o-mini(闭源,API)
Llama-3.1-8B-In & Llama-3.3-70B-In(开源,指令版)
Phi-4(14 B 开源,指令版)
提示策略
Zero-Shot:仅任务指令 + 题干
Few-Shot:每条模式给 1 例带标签(义务与认知分别独立样例)
Zero-Shot-CoT:指令末尾加 “Let’s think step by step.”,最大输出 1 024 token,末行截取 entailment/non-entailment
测量指标
主指标:Accuracy(%)
辅指标:
– 跨模式一致性:同一模型对互为逆否的推理对(Mu-Mi vs NotMi-NotMu)是否同时正确
– 内容效应差:Congruent − Incongruent 准确率差值
– 否定惩罚:含否定模式(MT/DA)与无否定模式(MP/AC)的准确率差值
补充分析
错误案例人工编码(图 4–11):定位“can choose to”被误解为“可选而非被允许”等语义偏差
显著性检验:McNemar 检验对比 Few-Shot vs Zero-Shot 在相同模型-任务上的提升/下降是否显著(p<0.01)
可重复性
温度=0,单轮输出,全部原始预测与代码开源至 https://github.com/kmineshima/NeuBAROCO
题目集合、提示模板、标签文件一并发布,可直接复现 90 组条件结果。
Q5: 有什么可以进一步探索的点?
以下方向可在此基础上继续深入,分为“数据-任务”“模型-算法”“认知-对齐”三大层面,均直接对应论文发现的缺口。
数据-任务层面
跨语言义务逻辑
当前仅英文。中文、日文等语言里“应该/可以/不得”的模态词分布与语义强度不同,可检验语言特异性是否导致新的不一致模式。
多步规范推理链
现有题目最长两步前提。引入三~五步的规范链(如“若 A 则必须 B;若 B 则允许 C;X 没有 C;问:X 是否违背 A?”),测试模型能否保持跨层传递一致性。
权重-冲突规范
真实场景常出现“必须 A”与“必须 ¬A”同时存在。构建带优先级的规范库(如法律例外、伦理原则排序),考察 LLM 能否做冲突消解与权重比较。
动态规范更新
引入对话式“规范修订”任务:初始规则集在交互中被取消或新增,模型需实时调整结论,检测其是否出现“规范遗忘”或“固执效应”。
模型-算法层面
符号-神经混合架构
将 Standard Deontic Logic 的公理作为软约束加入损失函数,或在推理阶段调用外部定理器(如Lean4、Z3)进行义务模态验证,再与生成答案对齐。
模态词向量空间探针
使用线性探针或表征工程方法,检查 OA、PA、¬PA 等模态表达式在隐藏态是否形成一致的格结构(Deontic Square),并尝试通过向量算术修正错误预测。
否定与量词解耦训练
论文显示否定是主要难点。可构建大规模“否定-仅”数据增强(paraphrase 含/不含否定),配合课程学习先易后难,观察能否降低 MT/DA 类错误。
对比式提示微调
对同一义务模式同时给“有效/无效”正反例,训练模型输出对比解释(为什么 OA⇒PA 成立而 PA⇒OA 不成立),提升其区分能力与可解释性。
认知-对齐层面
人机规范一致性校准
采集不同文化背景被试对 Ross 悖论、自由选择许可的直觉判断,建立“人类直觉分布”,再用 RLHF 把 LLM 对齐到该分布,而非纯粹逻辑标签。
规范推理与价值对齐联动
将义务推理错误率作为安全奖励信号:若模型在“不得伤害人类”→“允许不伤害人类”链路上出错,即视为潜在风险,实时触发安全策略更新。
认知偏差干预实验
借鉴心理学“去偏”技巧(如要求被试从第三方视角重述规则),设计相应元提示(meta-prompt),测量能否降低内容效应与否定惩罚。
可扩展规范监督
对于无法一次性标注的长链规范,用模型自我生成候选规则→义务定理器过滤自相矛盾部分→人工仅需审核剩余子集,实现低成本持续扩展。
立即可执行的 mini 项目
在现有 NeuBAROCO 上增加“动态更新” split:每条样本附加一条“规则撤销”语句,形成新标签,看 Zero-Shot 准确率下降幅度。
对 GPT-4o 的 CoT 错误输出做“反向提示”:把错误中间句作为负面提示再次提问,统计二次修正成功率,评估模型是否具备局部自修复能力。
用开源 7 B 模型在义务逻辑数据上做 LoRA 微调,仅训练 1 epoch,对比微调前后 Mu-Mi 与 NotMi-NotMu 一致性,验证“小剂量数据能否迅速修复断裂的 Deontic Square”。
以上任意一条均可作为毕业设计或 workshop 论文的起点,且数据与代码基线已公开,可直接 fork 复现。
Q6: 总结一下论文的主要内容
论文核心概述
题目:Normative Reasoning in Large Language Models: A Comparative Benchmark from Logical and Modal Perspectives
任务:系统评测大语言模型(LLM)在规范性/义务模态推理中的逻辑一致性,并与认知模态推理、人类认知偏差进行对照。
1. 研究动机
规范性推理(obligation, permission, prohibition)是 AI 对齐、法律与伦理应用的关键能力,但 LLM 此前缺乏专门的形式评测。
义务逻辑与认知逻辑共享模态结构,却分属“规范”与“知识”两域;LLM 在两域的表现差异未知。
人类在此类推理中呈现领域特异性、内容效应、否定敏感等偏差,LLM 是否复现尚待验证。
2. 构建基准 NeuBAROCO
任务t义务侧t认知侧t内容变量
Deontic Logict11 种单前提模式(含 Ross 悖论、自由选择)t8 种对应模式t符合/违背/无意义 ×20 实例
Syllogistict8 种双前提模式(MP/MT/AC/DA)t8 种对应模式t同上
总计t640 题t480 题t480+480 题
标签依据 Standard Deontic Logic / 认知逻辑 K、T 系统;争议模式额外参考人类直觉。
3. 实验设计
模型:GPT-4o、GPT-4o-mini、Llama-3.1-8B-In、Llama-3.3-70B-In、Phi-4
提示:Zero-Shot / Few-Shot / Zero-Shot-CoT,温度=0,单轮 deterministic
指标:Accuracy、跨模式一致性、内容效应差、否定惩罚
4. 主要发现
基础推理断裂
即使最佳模型(GPT-4o)在“义务→许可”OA⇒PA 仅 56 %,却几乎 100 % 正确完成其逆否 ¬PA⇒¬OA,暴露逻辑不一致。
否定敏感
含否定前提的 MT/DA 模式比 MP/AC 低 20–40 %,证实否定难度 > 有效/无效区别。
内容效应
结论违背常识时准确率下降 10–20 %,与人类偏差一致;无意义词进一步降低性能。
领域特异性反转
三段论任务义务侧略易(符合人类社会推理优势),但义务逻辑整体更难,说明“领域易度”依赖任务类型。
提示策略局限
Few-Shot 可提升但可能依赖表层匹配;CoT 常引入中间步错误,反而降低或持平准确率。
5. 结论与启示
当前 LLM 在规范性推理上尚未达到可部署的逻辑一致性。
错误模式复现人类认知偏差,提示未来对齐工作需同时考虑形式公理与人类直觉分布。
数据、代码、提示模板全部公开,供后续研究迭代。
阅读全文 →
来源:Arxiv2025-10-30 15:35:13 UTC

